728x90
연관 규칙 분석을 위한 데이터 준비 방법
[연관 규칙 데이터 정제] 데이터를 정제하여 apriori 알고리즘을 수행하기 위한 준비
Data Source: https://www.kaggle.com/datasets/rashikrahmanpritom/groceries-dataset-for-market-basket-analysismba?resource=download&select=Groceries+data.csv In [11]: import os import pandas as pd In [12]: os.chdir('C:/Users/KANG/Downloads') os.getcwd() Out[
knote.tistory.com
In [1]:
from matplotlib import font_manager, rc
font_path = "C:\\ProgramData\\Anaconda3\\lib\\site-packages\\matplotlib\\mpl-data\\fonts\\ttf\\BMJUA_ttf.ttf"
font = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font)
. 마케팅을 위한 연관 규칙(association_rules) 분석¶
01. 데이터 소개 및 분석프로세스 수립¶
사전 처리된 데이터 basket.csv
02. 데이터 준비를 위한 EDA 및 전처리¶
0. 데이터 불러오기¶
In [2]:
############################################## 00. 필요한 파이썬 라이브러리 불러오기 #####################################################
import numpy as np
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
%matplotlib inline
import squarify # tree map
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
from wordcloud import WordCloud
# Import and suppress warnings
import warnings
warnings.filterwarnings('ignore')
Matplotlib 트리맵 그리기
In [3]:
import os
os.chdir('../')
os.getcwd()
Out[3]:
'C:\\Users\\KANG\\PYTHON\\py_study\\python_projects'In [4]:
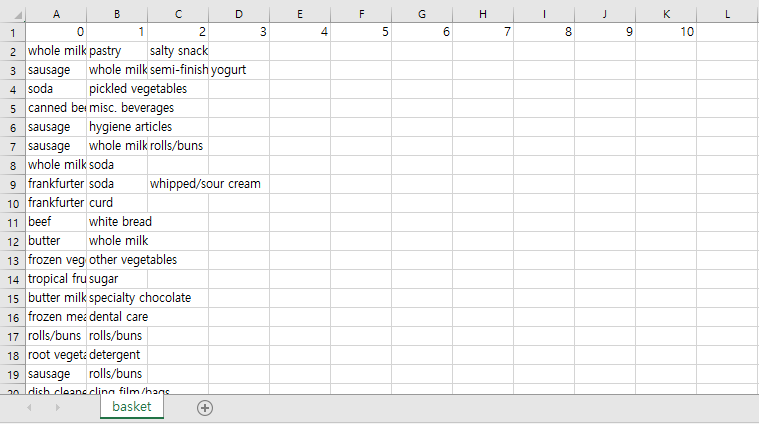
data = pd.read_csv('./basket.csv', header = 0)
data.head()
Out[4]:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | whole milk | pastry | salty snack | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | sausage | whole milk | semi-finished bread | yogurt | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | soda | pickled vegetables | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | canned beer | misc. beverages | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | sausage | hygiene articles | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
In [5]:
# 데이터의 모양 알아보기
data.shape
Out[5]:
(14963, 11)In [6]:
# 랜덤 샘플 데이터 보기
data.sample(10)
Out[6]:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 11035 | baking powder | frozen potato products | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 8909 | rolls/buns | bottled beer | dishes | pip fruit | whole milk | hard cheese | brown bread | soda | NaN | NaN | NaN |
| 14886 | canned beer | berries | bottled water | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4122 | rolls/buns | soda | other vegetables | vinegar | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 10805 | rolls/buns | sausage | curd | whole milk | butter milk | margarine | white bread | yogurt | NaN | NaN | NaN |
| 10164 | hard cheese | shopping bags | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 10034 | hamburger meat | coffee | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1513 | pip fruit | pot plants | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 9796 | cream cheese | salt | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 9136 | chicken | frozen vegetables | candles | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
1. 데이터 탐색¶
1) 데이터 타입¶
In [7]:
# 컬럼별 데이터 타입 알아보기
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 14963 entries, 0 to 14962
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 0 14963 non-null object
1 1 14963 non-null object
2 2 4883 non-null object
3 3 2185 non-null object
4 4 795 non-null object
5 5 451 non-null object
6 6 276 non-null object
7 7 196 non-null object
8 8 51 non-null object
9 9 1 non-null object
10 10 1 non-null object
dtypes: object(11)
memory usage: 1.3+ MB
2) 데이터 통계값¶
In [8]:
# 컬럼별 간단한 통계값 보기
data.describe()
Out[8]:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 14963 | 14963 | 4883 | 2185 | 795 | 451 | 276 | 196 | 51 | 1 | 1 |
| unique | 165 | 165 | 154 | 146 | 126 | 101 | 88 | 72 | 35 | 1 | 1 |
| top | whole milk | whole milk | whole milk | whole milk | whole milk | shopping bags | yogurt | whole milk | shopping bags | curd | newspapers |
| freq | 1083 | 983 | 244 | 111 | 39 | 25 | 19 | 14 | 4 | 1 | 1 |
3) 인기 판매 상품 시각화¶
WordCloud¶
In [9]:
data.columns = data.columns.astype('int64')
In [10]:
plt.rcParams['figure.figsize'] = (10, 10)
wordcloud = WordCloud(background_color = 'white', width = 1200,
height = 1200, max_words = 121).generate(str(data[0]))
plt.imshow(wordcloud)
plt.axis('off')
plt.title('인기 판매 상품들',fontsize = 20)
plt.show()

In [11]:
plt.rcParams['figure.figsize'] = (12, 8)
color = plt.cm.copper(np.linspace(0, 1, 40))
data[0].value_counts().head(40).plot.bar(color = color)
plt.title('인기 판매 상품들', fontsize = 20)
plt.xticks(rotation = 90 )
plt.grid()
plt.show()

트리맵¶
In [12]:
y = data[0].value_counts().head(50).to_frame() # 시리즈를 데이터 프레임으로 만들기
y.index
Out[12]:
Index(['whole milk', 'other vegetables', 'sausage', 'tropical fruit',
'rolls/buns', 'citrus fruit', 'root vegetables', 'soda', 'frankfurter',
'pip fruit', 'pork', 'yogurt', 'canned beer', 'beef', 'chicken',
'bottled water', 'pastry', 'bottled beer', 'hamburger meat', 'ham',
'meat', 'whipped/sour cream', 'berries', 'butter', 'curd',
'brown bread', 'dessert', 'coffee', 'onions', 'newspapers', 'UHT-milk',
'fruit/vegetable juice', 'beverages', 'domestic eggs', 'shopping bags',
'ice cream', 'margarine', 'misc. beverages', 'cream cheese ',
'white bread', 'chocolate', 'butter milk', 'frozen vegetables',
'frozen meals', 'grapes', 'specialty chocolate', 'specialty bar',
'salty snack', 'oil', 'sugar'],
dtype='object')In [13]:
plt.rcParams['figure.figsize'] = (16, 16)
color = plt.cm.cool(np.linspace(0, 1, 50))
squarify.plot(sizes = y.values, label = y.index, alpha=.8, color = color)
plt.title('인기 판매 상품들 트리맵')
plt.axis('off')
plt.show()

4)결측값 5) 중복값 - 사전 데이터에서는 생략¶
2. 데이터 전처리¶
1) 데이터 컬럼명 수정¶
In [14]:
data.shape
Out[14]:
(14963, 11)In [15]:
# 동일한 크기의 리스트에 각 손님들의 쇼핑 목록을 넣기
trans = []
for i in range(0,14963):
trans.append([str(data.values[i,j]) for j in range(0, 11)])
# numpy array 로 변환
trans = np.array(trans)
print(trans.shape)
(14963, 11)
2) Transaction Encoder 적용¶
In [16]:
from mlxtend.preprocessing import TransactionEncoder
te = TransactionEncoder()
data = te.fit_transform(trans)
data = pd.DataFrame(data, columns = te.columns_)
data.shape
Out[16]:
(14963, 168)In [17]:
data.head()
Out[17]:
| Instant food products | UHT-milk | abrasive cleaner | artif. sweetener | baby cosmetics | bags | baking powder | bathroom cleaner | beef | berries | ... | turkey | vinegar | waffles | whipped/sour cream | whisky | white bread | white wine | whole milk | yogurt | zwieback | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | False | False | False | False | False | False | False | False | False | ... | False | False | False | False | False | False | False | True | False | False |
| 1 | False | False | False | False | False | False | False | False | False | False | ... | False | False | False | False | False | False | False | True | True | False |
| 2 | False | False | False | False | False | False | False | False | False | False | ... | False | False | False | False | False | False | False | False | False | False |
| 3 | False | False | False | False | False | False | False | False | False | False | ... | False | False | False | False | False | False | False | False | False | False |
| 4 | False | False | False | False | False | False | False | False | False | False | ... | False | False | False | False | False | False | False | False | False | False |
5 rows × 168 columns
In [18]:
len(y.index)
Out[18]:
50In [19]:
# 기존 컬럼과 동일한 순서로 필터링
data = data[y.index]
03. 연관 규칙 분석¶
기저귀를 살때(A) 맥주를 사는(B) 경우
지지도 (support) : 데이터 전체에서 해당 물건을 고객이 구입한 확률
- 두 항목에 대한 거래수(동시 거래 수) / 전체 거래수
- P(A∩B) = 기저귀 + 맥주 동시 구매 수 / 전체 거래 수
신뢰도 (confidence) : 어떤 데이터를 구매했을 때 다른 제품이 구매될 조건부 확률
- 조건과 결과 항목을 동시에 포함하는 거래수 / 조건 항목을 포함한 거래수
- P(B│A) = P(A∩B)/P(A) = 지지도 / P(A) = 기저귀 + 맥주 / 기저귀
향상도 (lift) : 두 물건의 구입 여부가 독립인지 판단하는 개념
- 동시 거래 수 * 전체 거래 수 / A거래 수 * B 거래 수
- P(B│A)P(B) = P(A∩B)/P(A)P(B) = 신뢰도 / P(B) = (기저귀 + 맥주) * 전체 거래수 / 기저귀 * 맥주
예시) 거래1 : (기저귀,맥주,빵) / 거래2 : (기저귀,맥주) / 거래3 : (기저귀,빵,음료수) / 거래4 : (빵, 음료수, 커피) 일 때,
- lift(기저귀 , 맥주) = support(기저귀->맥주) / (support[기저귀] * support[맥주]) = confidence(기저귀->맥주) / support(맥주)
- lift(C,A) = 신뢰도 / 맥주 포함하는 거래수 = (2/3)/(2/4) = 1.33
1) Apriori 알고리즘 적용 절차¶
1. 모든 거래에서 발생하는 모든 항목에 대한 빈도 테이블을 생성¶
In [20]:
data.head()
Out[20]:
| whole milk | other vegetables | sausage | tropical fruit | rolls/buns | citrus fruit | root vegetables | soda | frankfurter | pip fruit | ... | chocolate | butter milk | frozen vegetables | frozen meals | grapes | specialty chocolate | specialty bar | salty snack | oil | sugar | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | True | False | False | False | False | False | False | False | False | False | ... | False | False | False | False | False | False | False | True | False | False |
| 1 | True | False | True | False | False | False | False | False | False | False | ... | False | False | False | False | False | False | False | False | False | False |
| 2 | False | False | False | False | False | False | False | True | False | False | ... | False | False | False | False | False | False | False | False | False | False |
| 3 | False | False | False | False | False | False | False | False | False | False | ... | False | False | False | False | False | False | False | False | False | False |
| 4 | False | False | True | False | False | False | False | False | False | False | ... | False | False | False | False | False | False | False | False | False | False |
5 rows × 50 columns
2. support 가 임의의 값보다 큰 것들로 필터링 및 중요 항목의 모든 가능한 조합을 만들기¶
In [21]:
frequent_itemsets = apriori(data, min_support = 0.01, use_colnames=True)
frequent_itemsets.sort_values("support", ascending=False).head()
Out[21]:
| support | itemsets | |
|---|---|---|
| 0 | 0.157923 | (whole milk) |
| 1 | 0.122101 | (other vegetables) |
| 4 | 0.110005 | (rolls/buns) |
| 7 | 0.097106 | (soda) |
| 11 | 0.085879 | (yogurt) |
3. 모든 조합의 발생 횟수 계산¶
In [22]:
frequent_itemsets['length'] = frequent_itemsets['itemsets'].apply(lambda x: len(x))
frequent_itemsets.head()
Out[22]:
| support | itemsets | length | |
|---|---|---|---|
| 0 | 0.157923 | (whole milk) | 1 |
| 1 | 0.122101 | (other vegetables) | 1 |
| 2 | 0.060349 | (sausage) | 1 |
| 3 | 0.067767 | (tropical fruit) | 1 |
| 4 | 0.110005 | (rolls/buns) | 1 |
In [23]:
frequent_itemsets[ (frequent_itemsets['length'] == 2) &
(frequent_itemsets['support'] >= 0.01) ]
Out[23]:
| support | itemsets | length | |
|---|---|---|---|
| 50 | 0.014837 | (whole milk, other vegetables) | 2 |
| 51 | 0.013968 | (whole milk, rolls/buns) | 2 |
| 52 | 0.011629 | (whole milk, soda) | 2 |
| 53 | 0.011161 | (whole milk, yogurt) | 2 |
| 54 | 0.010559 | (other vegetables, rolls/buns) | 2 |
In [24]:
frequent_itemsets[ (frequent_itemsets['length'] == 1) &
(frequent_itemsets['support'] >= 0.1) ]
Out[24]:
| support | itemsets | length | |
|---|---|---|---|
| 0 | 0.157923 | (whole milk) | 1 |
| 1 | 0.122101 | (other vegetables) | 1 |
| 4 | 0.110005 | (rolls/buns) | 1 |
2) Association Rules 적용¶
In [25]:
df_ar = association_rules(frequent_itemsets, metric = "confidence", min_threshold = 0.1)
df_ar.sort_values("confidence", ascending=False)
Out[25]:
| antecedents | consequents | antecedent support | consequent support | support | confidence | lift | leverage | conviction | |
|---|---|---|---|---|---|---|---|---|---|
| 3 | (yogurt) | (whole milk) | 0.085879 | 0.157923 | 0.011161 | 0.129961 | 0.822940 | -0.002401 | 0.967861 |
| 1 | (rolls/buns) | (whole milk) | 0.110005 | 0.157923 | 0.013968 | 0.126974 | 0.804028 | -0.003404 | 0.964550 |
| 0 | (other vegetables) | (whole milk) | 0.122101 | 0.157923 | 0.014837 | 0.121511 | 0.769430 | -0.004446 | 0.958551 |
| 2 | (soda) | (whole milk) | 0.097106 | 0.157923 | 0.011629 | 0.119752 | 0.758296 | -0.003707 | 0.956636 |
728x90
'Data Analytics with python > [Machine Learning ]' 카테고리의 다른 글
| [Dimension Reduction] PCA components 기반 변환 (0) | 2023.02.13 |
|---|---|
| [연관 규칙 데이터 정제] 데이터를 정제하여 apriori 알고리즘을 수행하기 위한 준비 (0) | 2023.02.03 |
| [회귀 구현] data : california_housing (0) | 2023.02.02 |
| [학습 01] 주택 가격 예측하기 (1) | 2023.02.01 |
| [이미지 분할] Image segmentation (1) | 2023.01.26 |




댓글