비지도 학습에 속한다.
비슷한 위치에 있는 데이터들을 그룹으로 묶어 군집화 한다.
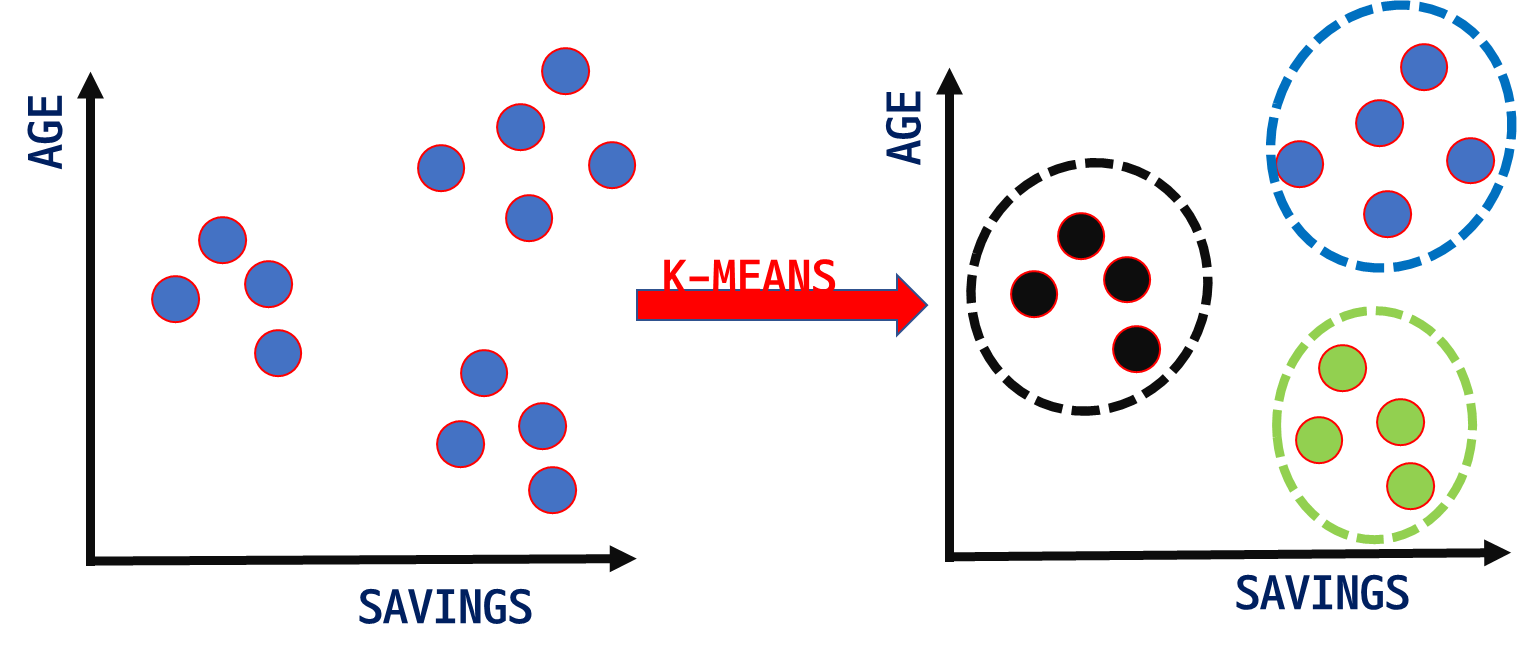
두 가지 변수에 속한 데이터 값들을 그룹핑 하는 경우
타겟 레이블이 없고 여러 데이터 값들만 있는 상태에서 군집화가 가능하다.
데이터들을 관찰하고 유클리드 거리값이 비슷한 데이터들 간에 묶는 과정을 거친다.
K-Means 알고리즘 단계

step1. 군집의 수를 정합니다. k
step2. 각 군집의 중심이 될 랜덤 k의 지점을 선택합니다.
step3. 정한 중심으로 근처에 있는 데이터를 할당하여 k개의 군집을 만듭니다.
step4. 각 군집의 새로운 중심을 계산합니다.
step5. 각각의 데이터들을 새로운 근처의 중심에 재할당합니다.
step6. step4부터 반복합니다.
최적의 k숫자
ELBOW METHOD: 최적의 군집 수를 얻기 위한 기법

군집 내 제곱의 합을 구한다. (Within Cluster Sum of Squares 약어 WCSS)
WCSS는 각 데이터 좌표들과 중심점의 거리를 계산하고 제곱합니다.
군집별로 똑같은 계산을 합니다.
모든 계산한 값을 합하면 구해집니다.
군집 수가 작을 수록, 군집 내 제곱 합은 매우 커지게 됩니다.
각 데이터 좌표들의 거리가 중심과 훨씬 멀어지기 때문입니다.
군집의 수를 늘려가면서 WCSS값은 점차 줄어듭니다. 각 데이터 좌표와 중심 간의 거리가 짧아지기 때문입니다.
제곱한 값들을 모두 더해도 값이 커지지 않습니다.
그러므로 최적의 K는 군집의 수가 점점 늘어날수록 낮아지는데 그 다음의 변화가 미미해지는 시작점이 최적이 됩니다.
'Data Analytics with python > [Theory]' 카테고리의 다른 글
| [Machine Learning][Classification] Classifier Algorithms (0) | 2023.02.16 |
|---|---|
| [Machine Learning][Classification] Ensemble Learning (0) | 2023.02.15 |
| [Machine Learning] 실루엣 분석 (0) | 2023.02.14 |
| [Machine Learning] K-means_1 (0) | 2023.02.14 |
| [Machine Learning] 차원 축소 (1) | 2023.02.13 |




댓글